Recommender System with Rapid Miner
User k-NN Collaborative Filtering for Item Recommendations - A step by step guide in Rapid Miner

As part of a class for NYU, a team of 3 of us are building a recommendation system for books. To quickly prototype a dead simple recommender system, we put together a simple Rapid Miner workflow. You can read more about this here at Doruk Kilitcioglu’s blog. Below are is the step by step guide we used to get results from Rapid Miner for item recommendations using user-user collaborative filtering.
-
Download
ratings.csvfrom http://fastml.com/goodbooks-10k-a-new-dataset-for-book-recommendations/-
NOTE: If you don’t have an educational license with RapidMiner, you can only load in 10k rows. Open and edit the ratings file and trim it down to 10k rows.
-
You can get an education license from the RapidMiner website if you make an account and add an .edu email
-
-
Download RapidMiner and install to your machine
-
Start a New Process and make it Blank
-
Loading the Data
-
Hit
Add Dataat the top left under repository -
Click on My Computer and find ratings.csv from your local machine
-
Hit all the
Nextbuttons and then save the file underdata -
This might take up to a minute
-
From the top left, expand Local Repository, then data, and then drag ratings.csv to the right window
-
-
6million ratings is too much for RapidMiner to process so let’s filter it down
-
Find the
Filter Examplesoperator and drag to the right window -
Hook up the output of Retrieve ratings to the input of
Filter Examples -
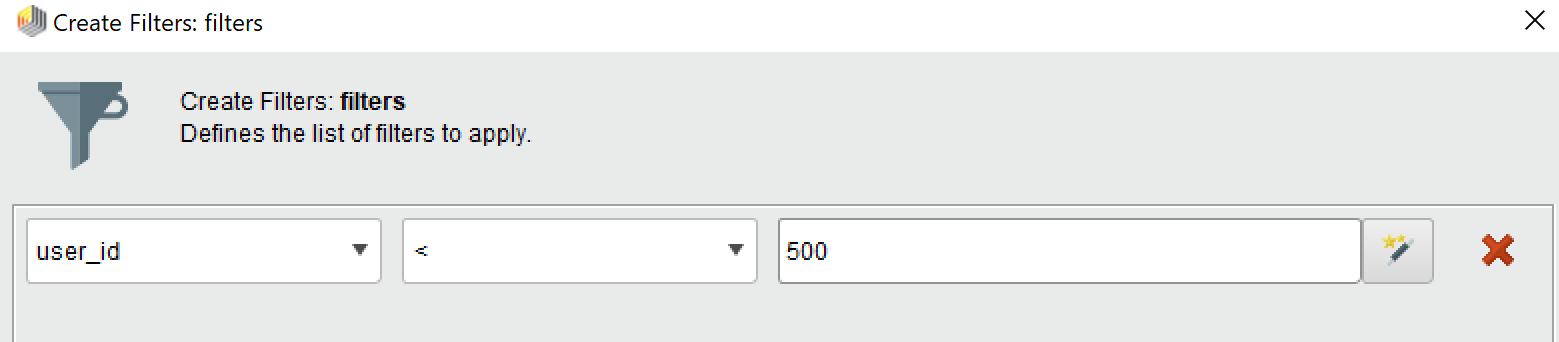
Click on
Filter Examplesand click on the Add Filters button to the far right -
Ensure user_id is selected as the left field
-
Make the filter operator (should be
=by default) a< -
Type in anywhere between
500to1000 -
Hit
OK
-
-
Set the role of the columns
-
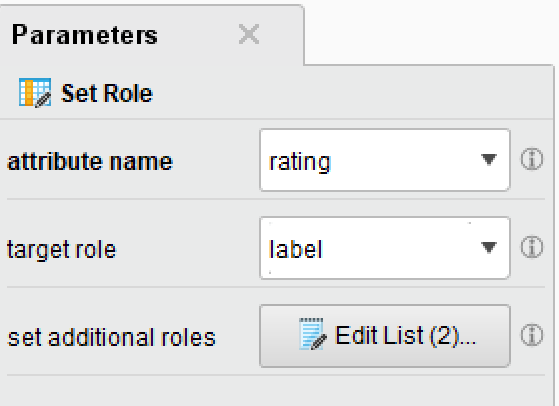
Add the
Set Roleoperator to the window -
Click on the box
-
At the far right, from the
attribute namedrop down, selectratingand set the target role tolabel
-
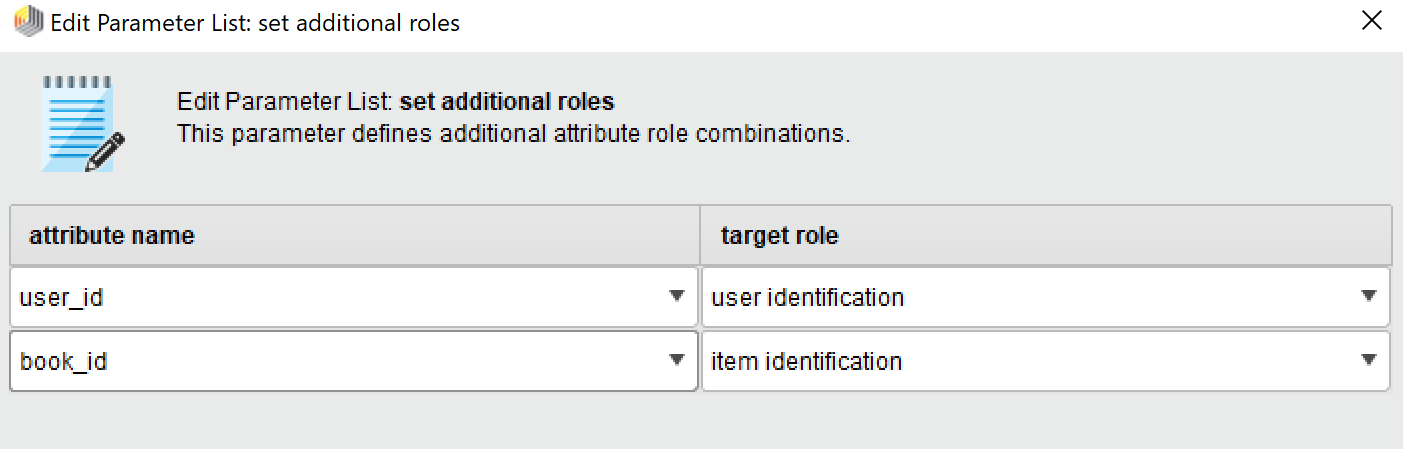
Click on the
Edit Listbutton-
Make the left field
user_idand at the right field, TYPE inuser identification -
At the bottom hit
Add Entry -
Made the new left field
book_idand at the right field, TYPE initem identification
-
-
Hit
Apply
-
-
Split data into
trainandtest-
Add the
Split Dataoperator to the right window -
Hook up output of
Set RoletoSplit Data -
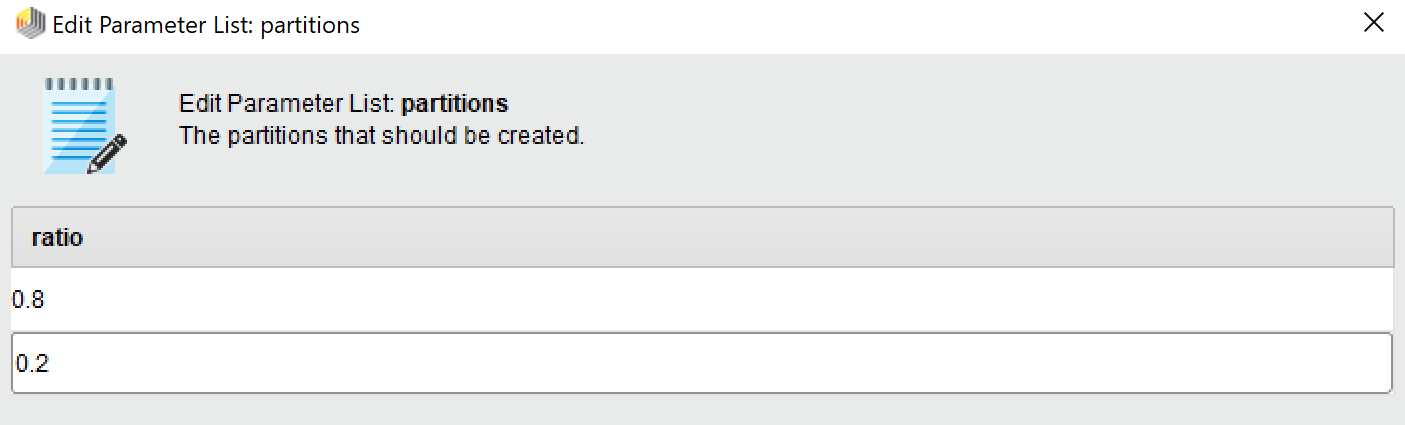
Click on
Split Dataand hit theEdit Enumerationbottom in the top right -
Add two entries
-
Type in the first one as .8 (this is the train set)
-
Type in the second one as .2 (this is the test set)
-
Hit
OK
-
-
Add Recommender System algorithm
-
At the very top right, hit
Extensionsand go to the Marketplace -
Type
Recommenderin the search bar -
Install
Recommender Extensionand follow the instructions to install
-
-
Add User k-NN item recommender system
-
Find the
Collaborative Filtering Item Recommendation/ User k-NN operator(will be inExtensionsunderRecommenders/Item Recommendation) -
Drag this to the right window
-
Hook up the top output of the
Split Databox to the input of theUser k-NNbox
-
-
Apply the model to train and test
-
Add
Apply Model (Item Recommendation)operator to the right window -
Hook up the
Modoutput of the User k-NN to the inputModof theApply Modelbox -
Hook up the second
paroutput of theSplit Databox to thequeinput of theApply Modelbox -
Drag the
resoutput of theApply Modelbox to thereson the very far right of the window (the final output)
-
-
Hit the big blue
Runbutton to view the output!- The model will recommend items (books) to users based on the books other users very similar to them have read
-
Please view the image below if you are stuck

-
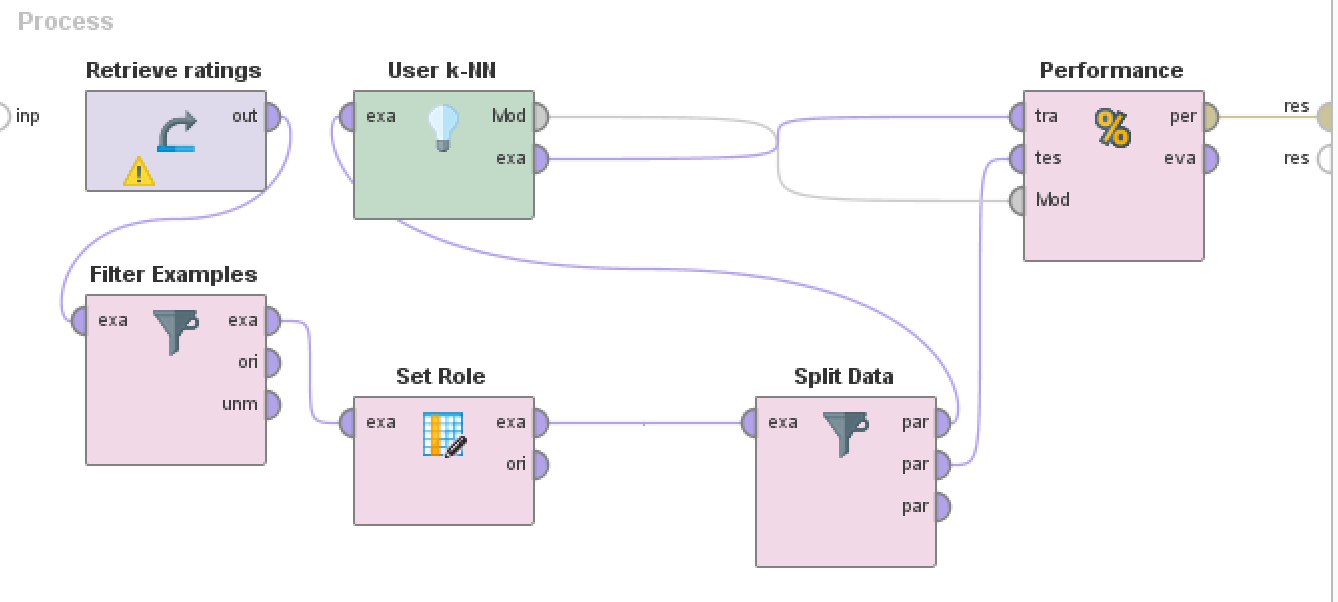
View performance metrics
-
Delete the
Apply Modelbox -
Add the
Performance (Item Recommendation)operator -
Hook up the
Modoutput of theUser k-NNbox to theModinput of thePerformancebox -
Hook up the
exaoutput of theUser k-NNbox to thetrainput of thePerformancebox -
Hook up the second
paroutput of the Split Data box to thetesinput of the Performance box -
Hoop up the
peroutput of the Performance box to theresat the very far right of the window
-
-
Hit the big blue
Runbutton to view the output!-
The output will be a slew of performance metrics for the Item Recommendations
-
The AUC (Area Under of the Curve) can be treated as an
accuracymetric
-
-
Please view the image below if you are stuck
Notes and further exploration:
-
You can use this set up on any set of ratings as long as the input csv follows the following format (User_id, item_id, rating) and you make sure to set the roles to exactly
user identification,item identificationandlabelas explained in the steps above -
You can predict the ratings on the test set instead of predicting good recommendations. Swap out the
Item Recommendation User k-NNwithRating Prediction User k-NNif you would rather predict the ratings that users have given their books -
Play around with Item k-NN or other operators. These operators find items that are most similar to other items in order to make recommendations. What we used above found most similar users to other users in order to recommend items
- Please read more on recommender systems and techniques to make them. This post is meant to be a step by step guide for RapidMiner and not an explanation on recommender systems